
Name-Catch
名寄せ処理プログラム
名寄せ処理プログラム
「Name-Catch」
ネーム・キャッチ
ノウハウが詰まった表記統一により
高精度な重複グループ抽出を実現
名寄せは顧客・案件ごとに定義も条件も違ってきます。そしてその定義・条件に合わないデータの処理全てを既存のプログラムで対応することは困難です。しかし、一定レベルまでプログラムで事前処理することによってバラつきを減らし、共有可能なレベルで名寄せ対象候補を作成することは可能です。Name-Catchはそうした名寄せ・データ統合のソリューションをスムーズに進めるための事前処理を行う重複データ検出プログラムです。長年培ってきたデータクレンジング処理のノウハウがここに詰まっています。テキストファイルでのバッチ処理となるため、データベースの仕様は問いません。住所は「Address-Catch」を利用するため高精度の判定が可能です。
主な機能と特徴
- CSVテキストファイルで(バッチ)処理
- 重複データにグループ番号を付与して出力
- 項目の選択・組み合わせ条件が自由に
- 名寄せ用に事前整備(表記統一など)したデータも出力可(別途データを精査したい場合等に使用)
- 住所処理(バーコードデータ化)は直接Address-Catch(住所整備プログラム)を呼び出すことが可能
組み合わせ自由な重複検出条件
重複検出条件は3項目・2項目・1項目の一致でそれぞれ処理が可能です。
- 3項目一致:[氏名] + [住所] + [電話番号]
- 2項目一致:[氏名] + [住所]/[氏名] + [電話番号]/[住所] + [電話番号]
- 1項目一致:[住所]/[電話番号]
設定できる項目の条件
| 項目名 | 設定条件 |
| 氏名 | 姓・名1つになっている場合、姓・名2つに別れている場合、それぞれ指定できます。(姓名分割の機能はありません) |
| 住所1 | 住所は最大3分割で指定できます。これらに指定された項目に対してAddress-Catchを直接呼び出してカスタマーバーコードデータを取得します。既にバーコードデータを取得済みの場合は、住所項目指定は行わず、「カスタマーバーコード」項目を指定します。 |
| 住所2 | |
| 住所3 | |
| カスタマバーコード | 事前にカスタマバーコードが取得されている場合は、この項目を指定します。 |
| 電話番号 | 携帯電話・IP電話の番号が混在していてもデータしては受け付けます。 |
| OPT1 | 上記以外の情報を材料に使用したい場合(ステータスで状況を示す) |
| OPT2 |
※カスタマバーコードとは、郵便事業等で処理を効率化するために宛先住所を「郵便番号+住所表示番号」によってバーコードデータ化させたものです。
出力ファイルについて
Name-Catchは、入力ファイルに対して、2ファイル出力します。
- 重複検出ファイル:重複データにグループ番号を付与したファイル
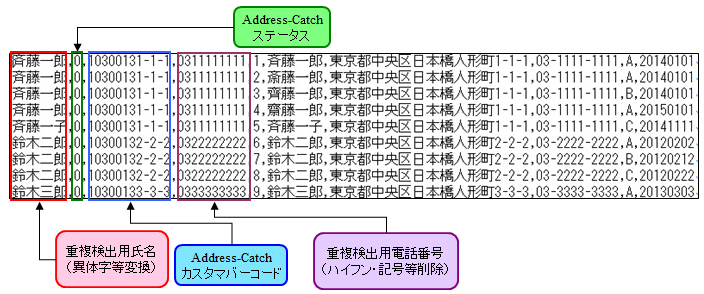
- 名寄せ用整備データ: Name-Catchで内部的に事前処理した重複検出用の統一変換データを出力します
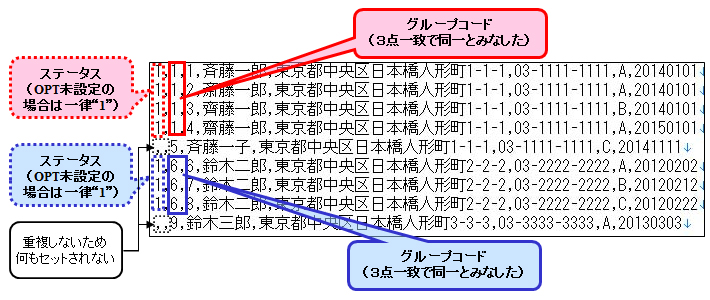
入力データ例
ID,氏名,住所,電話番号,区分,登録日
1,斉藤一郎,東京都中央区日本橋人形町1-1-1,03-1111-1111,A,20140101
2,斎藤一郎,東京都中央区日本橋人形町1-1-1,03-1111-1111,A,20140101
3,齊藤一郎,東京都中央区日本橋人形町1-1-1,03-1111-1111,B,20140101
4,齋藤一郎,東京都中央区日本橋人形町1-1-1,03-1111-1111,A,20150101
5,斉藤一子,東京都中央区日本橋人形町1-1-1,03-1111-1111,C,20141111
6,鈴木二郎,東京都中央区日本橋人形町2-2-2,03-2222-2222,A,20120202
7,鈴木二郎,東京都中央区日本橋人形町2-2-2,03-2222-2222,B,20120212
8,鈴木二郎,東京都中央区日本橋人形町2-2-2,03-2222-2222,C,20120222
9,鈴木三郎,東京都中央区日本橋人形町3-3-3,03-3333-3333,A,20130303
出力データ例(重複検出ファイル(3点項目一致で設定))
出力データ例(名寄せ用整備データ)
動作環境
システム(OS):Windows 10、Server2012/2016
HDD:1GB程度の空き容量(変換データの空き容量は含めない)
言語環境:富士通 NetCOBOL Base Edition 運用パッケージ(※)
:富士通 PowerSORT
※富士通 NetCOBOL運用パッケージはAddress-Catchの動作にも必要な環境です(共用できます)。
関連ブログ
- 名寄せとデータクレンジング①~「名寄せ」という言葉から連想するもの
- 名寄せとデータクレンジング②~名寄せの目的とその段取り
- 名寄せとデータクレンジング③~マッチング用項目の設定
- 名寄せとデータクレンジング④~マッチングデータの作成
- 名寄せとデータクレンジング⑤~重複グループの検出
- 名寄せとデータクレンジング⑥~どのようにデータを統合するか