
ブログ
データマネジメント
公開日:2021/11/03
エニイの事務局代行業務では紙の書類を多く取り扱っており、 紙媒体をデータベース化(データ入力)のご依頼も多くいただいております。
そこで、今回はデータ入力業務の課題である「作業効率化」・「正確性の向上」を目指し UiPathでMicrosoft OCRを使用して 画像から活字・手書き文字の読み込み~テキスト出力をしてみたいと思います。
まずOCR処理させたい画像を用意します。 今回はword作成した文書を印刷し、文字を書き加えてスキャンした画像を使用します。 
次にUiPathでワークフローを用意します。
「画像を読み込み」アクティビティ、「Microsoft OCR」アクティビティ、 「テキストをファイルに書き込み」アクティビティを下図の様に追加していきます。
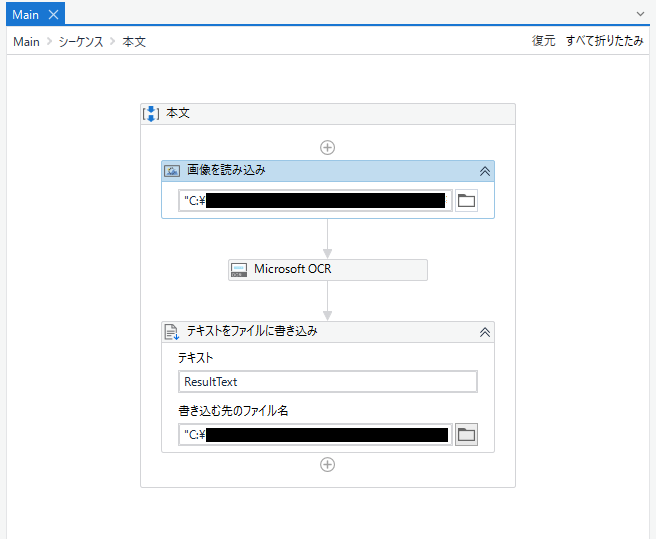
アクティビティを用意したらそれぞれプロパティを設定していきます。 変更したいアクティビティをクリックして画面右のプロパティパネルから設定を行います。
画像を読み込みアクティビティでは「ファイル名」と「画像」のプロパティを設定します。 「ファイル名」は OCR処理させたい画像のパスを設定します。 プロパティに文字列を直接設定する場合はダブルクォーテーション括りが必要なので 忘れないようにしましょう。(忘れているとエラー表示されます) 「画像」はMicrosoft OCRに受け渡す画像データの変数を設定します。
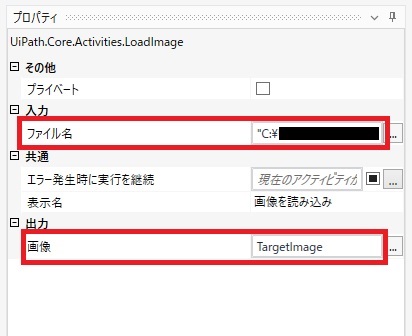
変数は入力欄から作成・設定ができます。 「画像」の入力欄 の上にカーソルを乗せるとプラスボタンが表示されるのでクリック ⇒表示されるメニューから「変数を作成」をクリック
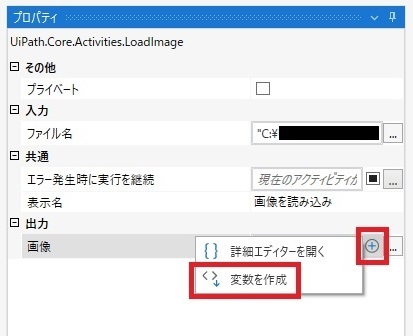
「変数を作成」をクリックすると入力欄に「変数を設定:」と表示されるので その右に変数名を入力すると変数が設定できます。 変数名は任意ですのでひとまず「TargetImage」としておきます。
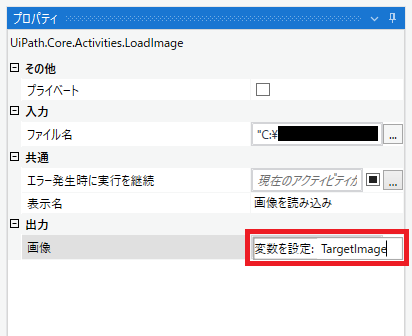
まずはMicrosoft OCRに処理させたい画像を受け渡す準備が出来ました。
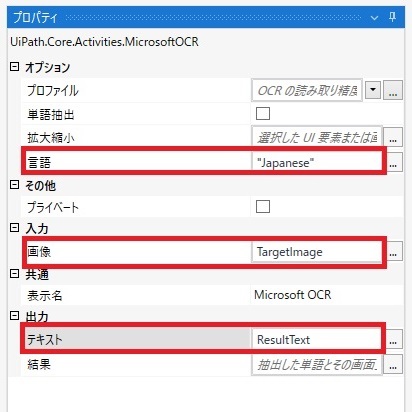
次のMicrosoft OCRアクティビティのプロパティは「言語」、「画像」、「テキスト」を設定します。
今回は日本語のOCRなので「言語」は「Japanese」、 「画像」にはOCRで処理させたい画像を設定するため、 先ほど画像読み込みアクティビティで設定した「画像」の変数を設定します。(ここではTargetImage) 「テキスト」にはOCRした結果のテキストデータを格納する変数を設定します。 画像読み込みアクティビティで設定したように変数を作成・設定すると楽です。 変数名はここでは「ResultText」としておきます。
これでMicrosoft OCRでOCR処理をする準備が出来ました。
最後にOCRした結果をテキスト出力するためにファイルを書き込みアクティビティのプロパティを設定します。 プロパティは「ファイル名」、「テキスト」を設定します。
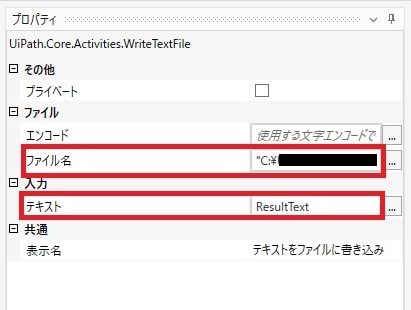
「ファイル名」には読み込んだテキストデータを出力するファイルのパスを設定します。 「テキスト」にはOCRした結果テキストを設定するため、 Microsoft OCRアクティビティで設定した「テキスト」の変数を設定します。 (ここでは「ResultText」)
これで指定画像をOCRしてテキスト出力する準備が完了です。 早速実行してみます。
実行はF5キーやデザインリボンの「実行」などから行えます。
結果は… 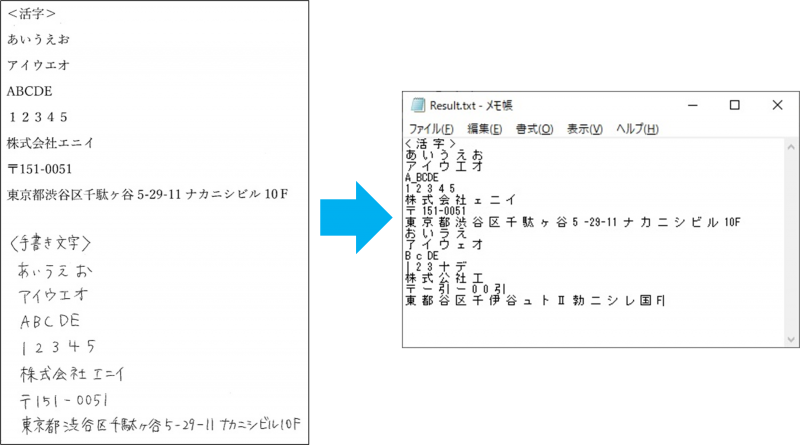
4行目のAとBの間にアンダーバー、6行目の会社名で「エ」が小文字になっていますが 活字はほぼ問題なく読み込めているようです。 手書き文字はなかなか厳しい結果です。
OCRの設定を変えて実行してみます。
MicrosoftOCRプロパティを開き、「プロファイル」の値を変更します。 ここではOCRの読み取り精度を向上させるための前処理環境プロファイルの設定を行います。
「プロファイル」の入力欄の上にカーソルを乗せると プロファイルについての説明と選択可能な値が表示されます。
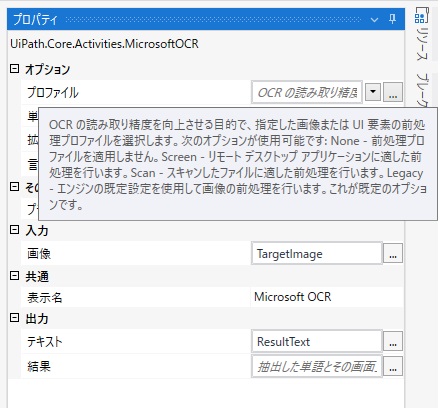
今回のような画像には「Scan」が向いているようなので「Scan」を設定します。
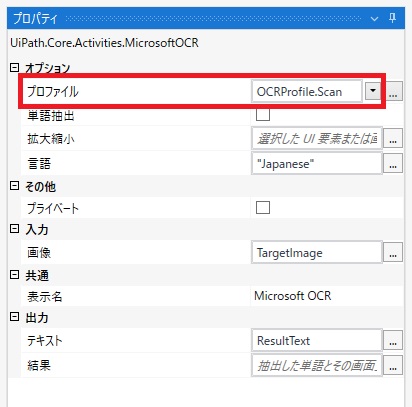
保存して再度実行します。
プロファイルがScanの場合の結果は… 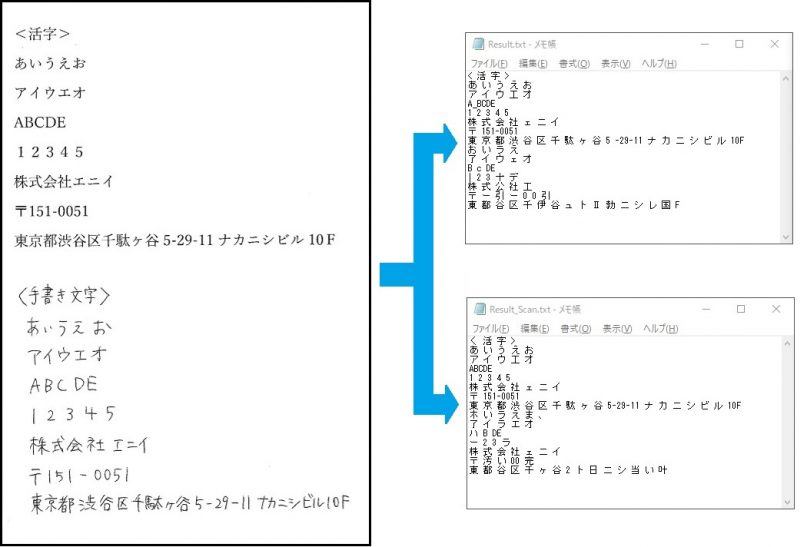
あまり変わらず…?
会社名はプロファイル設定なし時より読み込めていたり、 住所などで誤認識していたものは除外されて出力されるようですが カタカナ・アルファベット・数字は精度が少し下がっているようです。
フォントや文字サイズが混在していると精度が下がることがあるそうなので 画像から活字部分を除き、手書き文字だけでやってみます。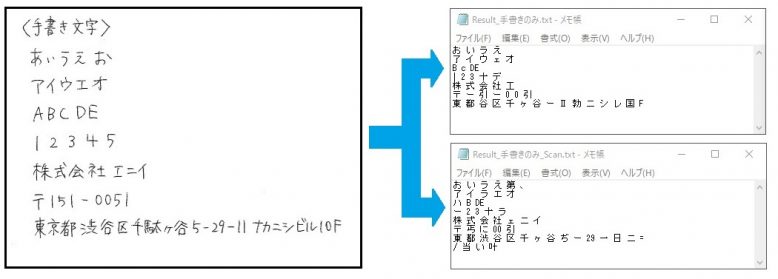
誤認識文字が除外されたり、 なかなか読み込まれなかった「渋」の字が出力されるようになっていますが、 「ナカニシビル10F」部分の文字が分解されたり2行になっています。 今回はフォントや文字サイズの混在は影響していないようです。
いくつか設定を変更してOCR処理をしてみましたが、 今回の結論としては活字はまずまずの読み込み具合、 手書き文字は課題ありといったところでしょうか。
手書き文字はOCRエンジンを変更したり設定次第で精度が上がる可能性があるそうなので 色々試してみるとよさそうです。
というわけでUiPathでのMicrosoft OCR処理のご紹介でした。